Apache Spark作(zuò)爲大(dà)數據處理(lǐ)和分(fēn)析領域的領先工(gōng)具,正日(rì)益成爲企業和組織處理(lǐ)海量數據的首選解決方案。本期将深入探討(tǎo)Apache Spark的核心概念和框架模型。
Spark是什麽
Spark是一個開源的大(dà)數據處理(lǐ)框架,旨在提供快(kuài)速、通用且易于使用的分(fēn)布式計(jì)算和數據處理(lǐ)能力。它由Apache Software Foundation開發和維護,構建在Hadoop生(shēng)态系統之上,但(dàn)相(xiàng)較于傳統的MapReduce模型,Spark提供了更高級别的API和更廣泛的功能。
Spark的主要目标是解決大(dà)數據處理(lǐ)中的速度和靈活性問(wèn)題。它通過在内存中進行數據處理(lǐ)和緩存,顯著提高了處理(lǐ)速度。Spark支持多種編程語言接口,包括Scala、Java、Python和R,使開發者能夠使用自(zì)己熟悉的語言進行大(dà)數據處理(lǐ)和分(fēn)析。
Spark框架模塊
Apache Spark框架由多個模塊組成,每個模塊提供不同的功能和API。以下是Spark框架的主要模塊:
- Spark Core:Spark Core是Spark框架的基礎模塊,提供了分(fēn)布式任務調度、内存管理(lǐ)、錯誤恢複和與存儲系統交互的基本功能。它定義了彈性分(fēn)布式數據集(RDD)的概念,并提供了RDD的創建、轉換和操作(zuò)的API。
- Spark SQL:Spark SQL模塊提供了用于結構化數據處理(lǐ)和SQL查詢的功能。它支持在Spark中執行SQL查詢,并提供了DataFrame和DataSet等高級數據結構,用于進行關系型和結構化數據的操作(zuò)。
- Spark Streaming:Spark Streaming模塊用于處理(lǐ)實時數據流。它基于微批處理(lǐ)的方式,将實時數據流劃分(fēn)爲小批次,并在每個批次上進行數據處理(lǐ)和分(fēn)析。這使得(de)Spark Streaming能夠處理(lǐ)實時數據,并提供可(kě)容錯的、高吞吐量的實時計(jì)算能力。
- MLlib:MLlib是Spark的機(jī)器學習庫,提供了豐富的機(jī)器學習算法和工(gōng)具。它包括分(fēn)類、回歸、聚類、推薦和協同過濾等常見(jiàn)機(jī)器學習任務的算法實現。MLlib還(hái)提供了特征提取、模型評估和數據預處理(lǐ)等功能。
- GraphX:GraphX是Spark的圖計(jì)算庫,用于處理(lǐ)和分(fēn)析大(dà)規模圖數據。它提供了圖的構建、遍曆、操作(zuò)和算法運算的API。GraphX支持頂點和邊的屬性,可(kě)以用于解決社交網絡分(fēn)析、推薦系統和圖形算法等問(wèn)題。
- SparkR:SparkR是Spark的R語言接口,允許使用R語言進行Spark應用程序開發和數據處理(lǐ)。它提供了基于R語言的DataFrame API,使R用戶能夠利用Spark的分(fēn)布式計(jì)算能力進行數據分(fēn)析和建模。
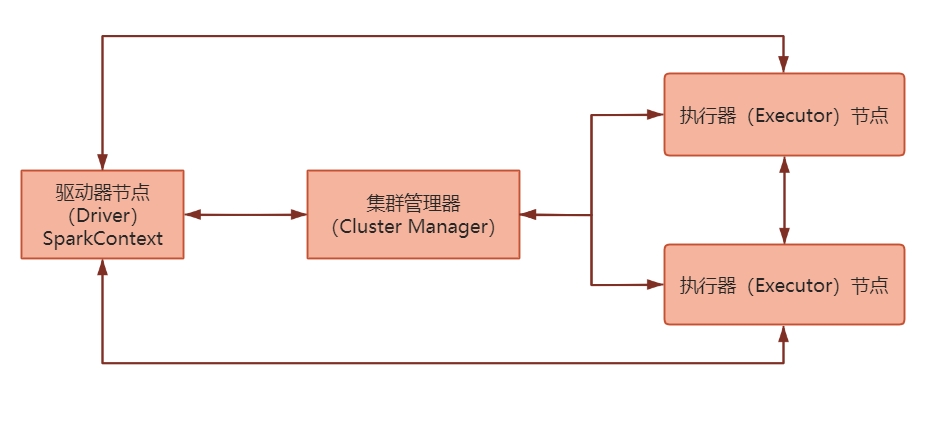
Spark集群模式架構
Spark集群模式架構通常涉及以下組件(jiàn)和角色:
- 驅動器節點(Driver):驅動器節點是Spark應用程序的控制節點,負責解析應用程序代碼、執行任務調度、管理(lǐ)資源分(fēn)配和協調工(gōng)作(zuò)節點。它通常運行在集群的一個節點上。
- 執行器節點(Executor):執行器節點是Spark應用程序的工(gōng)作(zuò)節點,負責執行實際的任務和計(jì)算。每個執行器節點都(dōu)在獨立的JVM進程中運行,并接收來(lái)自(zì)驅動器節點的任務指令。
- 集群管理(lǐ)器(Cluster Manager):集群管理(lǐ)器負責管理(lǐ)集群中的資源分(fēn)配和任務調度。它負責将任務分(fēn)配給可(kě)用的執行器節點,并監控它們的健康狀況。常見(jiàn)的集群管理(lǐ)器包括Spark自(zì)帶的獨立模式、Apache Hadoop YARN、Apache Mesos和Kubernetes。
- 分(fēn)布式存儲系統:Spark需要一個分(fēn)布式存儲系統來(lái)存儲數據和中間結果。常見(jiàn)的存儲系統包括Hadoop分(fēn)布式文件(jiàn)系統(HDFS)、Amazon S3、Apache Cassandra等。這些存儲系統可(kě)以提供數據的高可(kě)靠性和容錯性。
在集群模式下,Spark應用程序的工(gōng)作(zuò)流程如(rú)下:
- 驅動器節點啓動:Spark應用程序的驅動器節點在集群中的一個節點上啓動,驅動器程序負責加載應用程序代碼、創建SparkContext對象并與集群管理(lǐ)器進行通信。
- 資源分(fēn)配和任務調度:集群管理(lǐ)器根據可(kě)用的資源情況(如(rú)CPU、内存)将任務分(fēn)配給可(kě)用的執行器節點。執行器節點會啓動Spark執行器進程來(lái)接收任務。
- 任務執行:驅動器節點将任務分(fēn)發給執行器節點,執行器節點根據指令執行相(xiàng)應的計(jì)算任務。它們可(kě)以在本地或遠(yuǎn)程的數據分(fēn)區上執行任務,将結果返回給驅動器節點。
- 結果彙總和輸出:驅動器節點收集執行器節點返回的結果,并進行彙總和聚合。最後,應用程序可(kě)以将結果寫入存儲系統、打印到控制台或進行其他(tā)操作(zuò)。
Spark的四種運行模式
Spark 提供了多種運行模式,以适應不同的部署需求和環境。下面是 Spark 常見(jiàn)的四種運行模式:
- Local 模式:在本地機(jī)器上以單機(jī)模式運行Spark應用程序。這種模式适用于開發和調試階段,不需要分(fēn)布式計(jì)算和資源管理(lǐ)。在本地模式下,Spark應用程序将在單個JVM進程中運行。
- Standalone 模式:Spark的獨立模式是一種簡單的集群模式,其中Spark應用程序在獨立的Spark集群上運行。該模式适用于小規模集群,可(kě)以通過Spark自(zì)帶的集群管理(lǐ)器啓動和管理(lǐ)。獨立模式提供了資源管理(lǐ)和任務調度功能,可(kě)以在集群中的多個節點上并行執行任務。
- YARN 模式:Apache Hadoop YARN(Yet Another Resource Negotiator)是Hadoop的資源管理(lǐ)器,Spark可(kě)以在YARN上以集群模式運行。它利用YARN的資源管理(lǐ)和調度功能,将Spark作(zuò)爲YARN應用程序在Hadoop集群上運行。在YARN模式下,Spark應用程序可(kě)以與其他(tā)基于YARN的應用程序共享資源。
- Mesos 模式:Apache Mesos是一種通用的集群管理(lǐ)系統,可(kě)以用于在分(fēn)布式環境中運行多個應用程序。Spark可(kě)以在Mesos上以集群模式運行,利用Mesos的資源隔離(lí)和調度功能。Mesos模式下的Spark應用程序可(kě)以共享Mesos集群上的資源,并與其他(tā)Mesos應用程序共存。Spark on Mesos模式中,Spark程序所需要的各種資源,都(dōu)由Mesos負責調度。由于Mesos和Spark存在一定的血緣關系,Spark這個框架在進行設計(jì)開發的時候,就(jiù)充分(fēn)考慮到了對Mesos的充分(fēn)支持,因此,相(xiàng)對YARN而言,Spark運行在Mesos上會更加靈活、自(zì)然。
Spark編程模型
Spark編程模型基于彈性分(fēn)布式數據集,簡稱RDD,它是Spark的核心抽象概念。Spark編程模型的核心思想是基于RDD的轉換和行動操作(zuò),通過構建一系列的轉換操作(zuò)來(lái)定義計(jì)算邏輯,然後通過行動操作(zuò)來(lái)觸發實際的計(jì)算和獲取結果。下面來(lái)講述一下RDD的性質:
- 什麽是RDD?
RDD是一種具有容錯性基于内存的集群計(jì)算抽象方法,它代表一個分(fēn)布式的、不可(kě)變的、可(kě)容錯的數據集合,可(kě)以在Spark集群中的多個節點上并行操作(zuò)和處理(lǐ)。
-
RDD的五大(dà)特點
- 分(fēn)區:RDD邏輯上是分(fēn)區的,僅僅是定義分(fēn)區的規則,并不是直接對數據進行分(fēn)區操作(zuò),因爲RDD本身(shēn)不存儲數據。
- 隻讀(dú):RDD是隻讀(dú)的,要想改變RDD中的數據,隻能在現有的RDD基礎上創建新的RDD。
- 依賴:RDD之間存在着依賴關系,寬依賴和窄依賴。
- 緩存:如(rú)果在應用程序中多次使用同一個RDD,可(kě)以将該RDD緩存起來(lái),該RDD隻有在第一次計(jì)算的時候會根據血緣關系得(de)到分(fēn)區的數據。
- checkpoint:與緩存類似的,都(dōu)是可(kě)以将中間某一個RDD的結果保存起來(lái),隻不過checkpoint支持持久化保存。
-
如(rú)何構建RDD?
在Spark中,可(kě)以通過以下幾種方式構建RDD:通過 textFile(data):Spark支持從(cóng)各種外部數據源(如(rú)Hadoop HDFS、本地文件(jiàn)系統、數據庫等)讀(dú)取數據并創建RDD。可(kě)以使用
SparkContext對象的textFile方法讀(dú)取文本文件(jiàn),或使用其他(tā)合适的方法讀(dú)取其他(tā)類型的文件(jiàn)。from pyspark import SparkContext # 創建SparkContext對象,并指定本地模式和應用程序名稱 sc = SparkContext("local", "RDD_test") # 使用textFile方法讀(dú)取文本文件(jiàn)并創建RDD,并将結果賦值給rdd變量 rdd = sc.textFile("D:/sparkFile/text/file.txt")通過 parallelize(data): 可(kě)以使用
SparkContext對象的parallelize方法,将一個已有的數據集合(如(rú)列表、數組等)轉換爲RDD。from pyspark import SparkContext # 創建SparkContext對象,并指定了本地模式和應用程序名稱 sc = SparkContext("local", "RDD_test") # 創建一個數據集合data data = [1, 2, 3, 4, 5] # 使用parallelize方法将數據集合轉換爲RDD,并将結果賦值給rdd變量 rdd = sc.parallelize(data) -
RDD的操作(zuò)
RDD支持兩種類型操作(zuò),分(fēn)别是轉換操作(zuò)(Transformations)和行動操作(zuò)(Actions)。- Transformation轉換操作(zuò):
轉換操作(zuò)是對RDD進行處理(lǐ)和轉換的操作(zuò),它們不會立即執行,而是創建一個新的RDD作(zuò)爲結果。轉換操作(zuò)是惰性求值的,隻有在遇到行動操作(zuò)時才會觸發實際的計(jì)算。一些常見(jiàn)的轉換操作(zuò)包括map()、filter()、flatMap()、reduceByKey()等。這些操作(zuò)可(kě)以用于對RDD的元素進行映射、過濾、扁平化、聚合等操作(zuò),以便進行數據的轉換和處理(lǐ)。 - Actions行動操作(zuò):
行動操作(zuò)是對RDD進行實際計(jì)算并返回結果的操作(zuò),它們會觸發RDD的計(jì)算并返回最終結果。行動操作(zuò)會導緻Spark執行計(jì)算圖中的所有轉換操作(zuò),并将結果返回給驅動程序或寫入外部存儲系統。一些常見(jiàn)的行動操作(zuò)包括collect()、count()、reduce()、saveAsTextFile()等。這些操作(zuò)用于觸發RDD的計(jì)算并返回計(jì)算結果,或将結果保存到外部存儲系統中。
- Transformation轉換操作(zuò):
-
RDD的依賴關系
在Spark中存在兩種類型的依賴:
-
- 窄依賴:父RDD中的一個Partition最多被子RDD中的一個Partition所依賴。
- 寬依賴:父RDD中的一個Partition被子RDD中的多個Partition所依賴。
- RDD的持久化
RDD持久化是Spark中一種重要的性能優化技術(shù),它可(kě)以将RDD的計(jì)算結果緩存到内存或磁盤中,以便在後續的操作(zuò)中重用,這樣可(kě)以避免重複計(jì)算和提高任務執行效率。在Spark中,持久化RDD有兩種常見(jiàn)的方式:
-
- RDD的緩存
緩存是将RDD的計(jì)算結果存儲在内存或磁盤上的一種方式。當一個RDD的計(jì)算非常的耗時/昂貴(計(jì)算邏輯比較複雜)的時候,并且這個RDD需要被重複(多方)使用,可(kě)以考慮将該RDD的計(jì)算結果緩存起來(lái),便于後續的使用,從(cóng)而提升PySpark程序的運行效率。
-
- RDD的checkpoint檢查點
checkpoint類似緩存操作(zuò),隻不過緩存是将數據保存在内存或者磁盤當中,而checkpoint是将數據保存在磁盤或HDFS,主要是放(fàng)在HDFS上面。一旦構建好checkpoint之後,會将RDD間的依賴關系給删除/丢棄,因爲checkpoint提供了更加安全可(kě)靠的數據存儲方案。後續如(rú)果計(jì)算出現了問(wèn)題,可(kě)以直接從(cóng)checkpoint檢查點上恢複數據。
緩存與checkpoint的區别:
存儲位置:
-
- 緩存: 存儲在内存或者磁盤 或者 堆外内存中。
-
- checkpoint: 可(kě)以将數據存儲在磁盤或者HDFS上, 在集群模式下, 僅能保存到HDFS上。
生(shēng)命周期:
-
- 緩存:當程序執行完成後,或者手動調用unpersist緩存都(dōu)會被删除的。
-
- checkpoint: 即使程序退出後, checkpoint檢查點的數據依然是存在的, 不會删除, 需要手動删除。
血緣關系:
-
- 緩存: 不會截斷RDD之間的血緣關系, 因爲緩存數據有可(kě)能是失效, 當失效後, 需要重新回溯計(jì)算操作(zuò)。
-
- checkpoint: 會截斷掉依賴關系, 因爲checkpoint将數據保存到更加安全可(kě)靠的位置, 不會發生(shēng)數據丢失的問(wèn)題, 當執行失敗的時候, 也不需要重新回溯執行。
需要注意的是,緩存和檢查點都(dōu)是惰性操作(zuò),隻有在對RDD進行行動操作(zuò)時才會實際觸發緩存或檢查點的計(jì)算和存儲。